Enhance your LLM responses by integrating data from the Database
Text-to-SQL is a task in natural language processing (NLP) that aims to automatically generate Structured Query Language (SQL) queries from natural language text. With the rise of Large Language Models (LLMs) like GPT-3.5 and GPT-4, this field has greatly advanced, offering improved natural language understanding and the ability to generate high-quality SQL queries. In this blog post, we will explore how to text to SQL with LLM, including the technical challenges and the evolutionary process of text-to-SQL.
One of the main technical challenges in text-to-SQL is the ability to generalize proficiently across a broad spectrum of natural language questions. This requires the system to be able to adapt to unseen database schemas and to be able to handle ambiguous or unclear natural language queries. Another challenge is the formulation of the SQL query, which requires the system to be able to synthesize all identified components into a cohesive SQL query.
LLM-based text-to-SQL systems have shown great promise in recent years. These systems use pre-trained language models like GPT-3.5 and GPT-4 to generate SQL queries from natural language text. One example of an LLM-based text-to-SQL system is Google TAPAS, which is a pre-trained model-based Text2SQL system that specializes in working with tabular data.
In this blog post, we will explore the use of the Langchain Text-To-SQL agent and a local language model such as Codestral to generate SQL queries from natural language text. To further test the capabilities of language models in generating SQL queries, we also plan to experiment with Groq Llama 3.1 70B.
At a high-level view, the entire process is as follows:
User Query: The user asks a question in natural language, such as "How many employees live in Calgary?"
Convert to SQL: The language model (LLM) converts the user's question into a SQL query.
Execute Query: The LLM executes the SQL query.
Return Result: The LLM converts the query result back into natural language and returns it to the user.
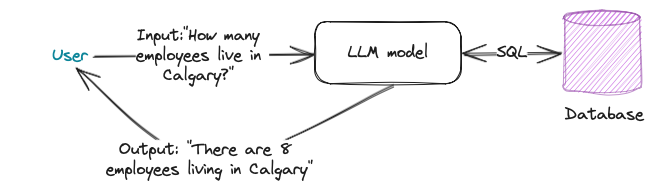
To begin, we'll use the Langchain Text-To-SQL agent to execute queries, followed by refining the results with the SQL Agent.
Step 1: Set Up Ollama
First, start your local Ollama instance with LLaMA 3.1.
Step 2: Install Required Libraries
Next, install the following Python libraries:
pip install langchain
pip install langchain-communityRecommended Tools: Conda and JupyterLab
We strongly advise installing and configuring Conda, a popular package manager, along with JupyterLab, a web-based interactive environment, to get the most out of your sandbox.
This will enable you to easily manage dependencies, reproduce results, and explore data in an intuitive and collaborative way.
Step 3: Create a Jupyter Notebook
Launch JupyterLab
Open your JupyterLab environment by navigating to the URL where it's running.
Create a New Notebook
Click on the "New" button to create a fresh notebook. You can choose from various templates or start with an empty one. In this notebook, add the following lines of code:
from langchain_community.llms import Ollamallm = Ollama( base_url='http://IP_ADDR:11434', model="llama3.1", temperature=0)Step 4: Set Up Chinook Database
Install SQLite and Chinook Database
Next, we'll use a SQLite connection with the Chinook database. To do this, follow these installation steps to create Chinook.db in the same directory as your notebook.
Note: The following diagram illustrates the structure of the Chinook database:

The Chinook.db file is now located in the same directory as your notebook. With the database file in place, you can interact with it using SQLite. You'll be able to execute SQL queries and manipulate data within the database. Additionally, you can connect to the Chinook.db file using DBeaver, a popular database management tool. This will allow you to explore the tables and their structures in a more visual and intuitive way.
Step 5: Execute Code Snippets
Adding Code
Next, add the following code snippets to your notebook:
import sqlite3from langchain_community.utilities import SQLDatabasedb = SQLDatabase.from_uri("sqlite:///Chinook.db")print(db.dialect)print(db.get_usable_table_names())db.run("SELECT COUNT(*) FROM Employee;")At this moment, if you run the notebook, you should get the following result.
sqlite['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']'[(8,)]Step 6: Convert User Question to SQL Query
Using Langchain Chain
Now, let's utilize the Langchain chain to convert the user's question into an equivalent SQL query.
This will involve feeding the user's question into the Langchain model and then extracting the resulting SQL query. We'll use this process to demonstrate how natural language inputs can be translated into structured database queries.
from langchain.chains import create_sql_query_chainchain = create_sql_query_chain(llm, db)response = chain.invoke({"question": "Who is the composer of the track Chemical Wedding"})responseThe above code should return the following output."SELECT Composer FROM Track WHERE Name = 'Chemical Wedding'"Step 7: Combine Query Result with User Question
Generating Final Answer
Now that we've established a way to generate SQL queries from natural language inputs, let's combine the query results with the user's original question to obtain a final answer.
To achieve this, we'll need to send the resulting query output back into our Large Language Model (LLM) for processing. This will allow us to generate a response that not only answers the user's question but also provides context and clarity based on the underlying data.
By integrating the query result with the LLM model, we can create a more comprehensive and informative answer that meets the user's needs.
from operator import itemgetterfrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import PromptTemplatefrom langchain_core.runnables import RunnablePassthroughanswer_prompt = PromptTemplate.from_template( """Given the following user question, corresponding SQL query, and SQL result, answer the user question.Question: {question}SQL Query: {query}SQL Result: {result}Answer: """)answer = answer_prompt | llm | StrOutputParser()chain = ( RunnablePassthrough.assign(query=write_query).assign( result=itemgetter("query") | execute_query ) | answer)chain.invoke({"question": "Who is the composer of the Album named 'Chemical Wedding'"})The output should be very similar as shown below:
The composer of the Album named 'Chemical Wedding is Bruce Dickinson.Note on Query Limitations
Not all query will work, for example "How many track in Album named 'Fireball'". To return the result, there should be inner join of two entities: track & album which not always works.
Here is the result of my queries:
How many employees are there who lives in Calgary?, works.
What is the name of the Artist of Album named 'Fireball'?, return error.
Who is the composer of the track Chemical Wedding, works.
What is the name of the album with track The Tower, works.
Step 8: Enhancing Interaction with LLM using Langchain SQL Agent
Optimizing Query Execution and Response Generation
In the final step, let's leverage the power of the Langchain SQL Agent to enhance our interaction with the Large Language Model (LLM). This tool is specifically designed within the Langchain framework to facilitate the conversion of natural language queries into SQL queries, execute those queries against a database, and then convert the results back into human-readable responses.
One of the key features that sets the Langchain SQL Agent apart is its ability to query the database as many times as needed to provide a comprehensive answer to the user's question. This means that even if the initial query doesn't yield the desired result, the agent can automatically refine its search and iterate through multiple queries to ensure that the final response accurately addresses the user's inquiry.
By integrating the Langchain SQL Agent into our system, we can significantly improve the accuracy and completeness of our responses, making it an invaluable tool for providing top-notch user experiences.
Add the following code into the notebook.
from langchain_community.agent_toolkits import create_sql_agent
from langchain.agents.agent_types import AgentType
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
agent_executor = create_sql_agent( llm=llm, toolkit=SQLDatabaseToolkit(db=db, llm=llm), verbose=True, agent_type="zero-shot-react-description", handle_parsing_errors=True)agent_executor.invoke("How many employees are there?")Note that, here we use "zero-shot-react-description" agent type to interact. verbose=True parameter will return the entire process of invoking the database and result combination.
> Entering new SQL Agent Executor chain...Thought: I should look at the tables in the database to see what I can query. Then I should query the schema of the most relevant tables.Action: sql_db_list_tablesAction Input: Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, TrackThought: I have the list of tables. I can see that there is an "Employee" table, which seems relevant to the question. I should query the schema of the "Employee" table to see what columns are available.Action: sql_db_schemaAction Input: EmployeeCREATE TABLE "Employee" ( "EmployeeId" INTEGER NOT NULL, "LastName" NVARCHAR(20) NOT NULL, "FirstName" NVARCHAR(20) NOT NULL, "Title" NVARCHAR(30), "ReportsTo" INTEGER, "BirthDate" DATETIME, "HireDate" DATETIME, "Address" NVARCHAR(70), "City" NVARCHAR(40), "State" NVARCHAR(40), "Country" NVARCHAR(40), "PostalCode" NVARCHAR(10), "Phone" NVARCHAR(24), "Fax" NVARCHAR(24), "Email" NVARCHAR(60), PRIMARY KEY ("EmployeeId"), FOREIGN KEY("ReportsTo") REFERENCES "Employee" ("EmployeeId"))/*3 rows from Employee table:EmployeeId LastName FirstName Title ReportsTo BirthDate HireDate Address City State Country PostalCode Phone Fax Email1 Adams Andrew General Manager None 1962-02-18 00:00:00 2002-08-14 00:00:00 11120 Jasper Ave NW Edmonton AB Canada T5K 2N1 +1 (780) 428-9482 +1 (780) 428-3457 andrew@chinookcorp.com2 Edwards Nancy Sales Manager 1 1958-12-08 00:00:00 2002-05-01 00:00:00 825 8 Ave SW Calgary AB Canada T2P 2T3 +1 (403) 262-3443 +1 (403) 262-3322 nancy@chinookcorp.com3 Peacock Jane Sales Support Agent 2 1973-08-29 00:00:00 2002-04-01 00:00:00 1111 6 Ave SW Calgary AB Canada T2P 5M5 +1 (403) 262-3443 +1 (403) 262-6712 jane@chinookcorp.com*/Thought: I have the schema of the "Employee" table. I can see that the table has an "EmployeeId" column, which is the primary key. To answer the question "How many employees are there?", I can simply count the number of rows in the "Employee" table.Action: sql_db_query_checkerAction Input: SELECT COUNT(*) FROM EmployeeSELECT COUNT(*) FROM EmployeeThought: I have checked the query and it looks correct. I can now execute the query to get the answer.Action: sql_db_queryAction Input: SELECT COUNT(*) FROM Employee[(8,)]Thought: I now know the final answerFinal Answer: There are 8 employees.> Finished chain.{'input': 'How many employees are there?', 'output': 'There are 8 employees.'}There are a few additional features, such as handling high-cardinality columns and the retriever tool, to enhance the results. Please refer to the LangChain SQL Agent page listed in the resources section for more information.
Resources: