Processing images step-by-step with LLaVA-v1.6
The field of artificial intelligence (AI) and machine learning has witnessed significant advancements in recent years, with the development of various tools and technologies that have transformed the way we approach complex tasks. One such tool is LLaVA-v1.6, a powerful AI model that has gained popularity among researchers and developers due to its capabilities in natural language processing and computer vision. In this article, we will provide a step-by-step guide on utilizing LLaVA-v1.6 for image visioning tasks, highlighting its significance, possibilities, and limitations.
Image visioning is a crucial aspect of AI, with applications in various fields such as healthcare, finance, and education. The ability to analyze and understand visual data has numerous benefits, including improved decision-making, enhanced customer experience, and increased efficiency. However, implementing image visioning tasks can be challenging, especially for those without prior experience. This is where LLaVA-v1.6 comes in – a powerful tool that simplifies the process of image visioning and provides accurate results.
What is LLaVA-v1.6?
----------------------
LLaVA-v1.6 is a deep learning-based AI model that specializes in natural language processing and computer vision. Developed by a team of researchers, LLaVA-v1.6 is designed to analyze and understand visual data, including images and videos. The model uses a combination of convolutional neural networks (CNNs) and recurrent neural networks (RNNs) to extract features from images and generate text-based descriptions.
LLaVA-v1.6 has a rich history, with its development dating back to 2019. Since its inception, the model has undergone several updates, with the latest version (v1.6) offering improved performance and accuracy. The key features of LLaVA-v1.6 include:
Image analysis: LLaVA-v1.6 can analyze images and extract features such as objects, scenes, and actions.
Text generation: The model can generate text-based descriptions of images, including captions and summaries.
Object detection: LLaVA-v1.6 can detect objects within images, including people, animals, and vehicles.
Possibilities and Functionalities of LLaVA-v1.6
------------------------------------------------
LLaVA-v1.6 has numerous possibilities and functionalities, making it a versatile tool for various applications. Some of the key applications of LLaVA-v1.6 include:
Image classification: LLaVA-v1.6 can classify images into different categories, such as objects, scenes, and actions.
Object detection: The model can detect objects within images, including people, animals, and vehicles.
Image captioning: LLaVA-v1.6 can generate text-based captions for images, including descriptions of objects, scenes, and actions.
LLaVa architecture and how it works?
In simple terms, here's how we can describe the LLaVa architecture:
Two Input Types: LLava can understand both text and images. Think of it as having two sets of eyes and ears – one for reading and one for seeing.
Text Processing: For text, LLava uses a language model (like a very advanced chatbot) to read and understand the words and sentences. This helps it know what you’re asking or talking about.
Image Processing: For images, LLava uses a vision model (like a smart camera) to look at and understand pictures. It can recognize objects, people, and scenes in the image.
Combining Information: LLava has a special way of combining what it reads and sees. It uses a "cross-modal attention mechanism," which is like focusing on the important parts of both the text and the image at the same time to understand the whole picture.
Understanding Context: By combining the text and image information, LLava builds a complete understanding of what’s going on. It understands how the words relate to the picture and vice versa.
Answering Questions: Once it understands everything, LLaVa can answer questions or provide information based on the text and images it has processed. It’s like having a conversation where it looks at pictures and reads text to give you the best answer.
Learning from Examples: LLava was trained using lots of examples that included both text and images. This training helped it learn how to connect words with pictures and come up with accurate answers.
In essence, LLaVa is like a smart assistant that can read and look at pictures at the same time to understand what you need and give you helpful responses.
From a technical perspective, the LLava architecture is as shown below.
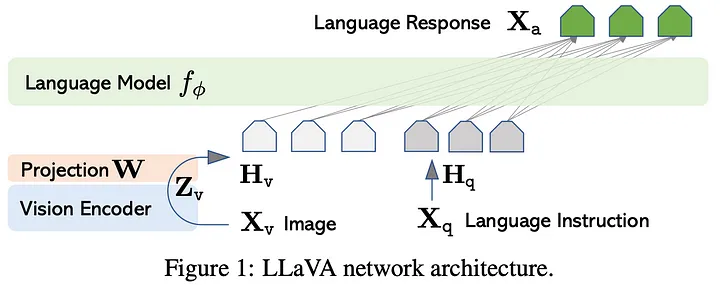
The image was taken from the official documentation of LLaVa https://arxiv.org/pdf/2304.08485.pdf.
The image describe the process of interacting with the LLaVa model where, user input an image along with a text prompt that contains instructions. The text prompt is processed directly by the language model's tokenizer while the image is first converted into tokens using a vision encoder. These tokens are then mapped to the space of the language model.
Step-by-Step Example: Utilizing LLaVA-v1.6 for Image Visioning
----------------------------------------------------------------
In this section, we will provide a step-by-step example of using LLaVa-v1.6 for image vision tasks. We will cover a few straightforward examples, such as describing images and extracting code or text from them.
Prerequisites
Software: You need to have Ollama installed and configured locally to use LLaVa-v1.6. If you need instructions on how to install Ollama, please refer to my previous post.
Hardware: A computer with a dedicated graphics card is recommended for faster processing. However, for educational purposes, an 8-core CPU will be sufficient.
Step 1: Installing and Setting Up LLaVA-v1.6
Run the following command in your terminal:
ollama run llava:34bThis command will download and install the LLava 1.6 LLM into your local Ollama setup. Please note that the llava:34b model requires more than 20 GB of free memory to run.
Step 2: Preprocessing and Preparing Image Data
Create a directory to store images by running:
mkdir imagesThen, copy a few images into the directory you just created. You can do this by using the cp command, for example:
cp /path/to/your/images/* images/Step 3: Implementing LLaVA-v1.6 for Image Visioning
Now, you can load the images into the LLaVa-v1.6 model and ask questions about them.
Describing images.

Prompt: what is in the image /path_to_the_image
In the terminal where Ollama run, execute the following command:
After a short wait, LLaVa returns the following answer:
The image shows a piece of furniture with a metal frame, which appears to be the footboard or headboard of a bed. The metal is dark in color and there are visible bolts and other hardware components that suggest the bed frame is sturdy and securely assembled. There's no text present in this image. If you have any questions about the type of bed frame or need advice on furniture, feel free to ask!Impressive result.
Understanding a digram or schema

Prompt: describe the diagram /path_to_the_imageResult:
The diagram appears to be a flowchart or an organizational chart, possibly representing a system or process with various components and data fields. It includes nodes connected by lines that suggest relationships or workflow between the elements. Each node is labeled with a title such as "Customer", "Employee", "Track", and others that seem to indicate different categories or entities within the system being represented.The diagram uses a dark background with white text and light-colored nodes, which creates a contrast for readability. The lines connecting the nodes are likely to represent the flow of information or the sequence of steps in the process. Each node has fields on it that seem to correspond to specific data points, such as customer ID, name, email, and so forth, suggesting that this diagram might be related to a software application or database schema where different entities have their own attributes and relationships.The image does not provide enough context to determine the exact nature of the system or process being represented in the flowchart, but it is clear that it is designed to show the structure and interconnectivity of various elements within that system.Let's try one more diagram.
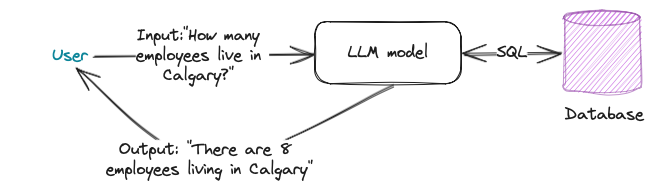
Prompt: Describe the meaning of the diagram /path_to_the_imageResult:
The image you've shared appears to be a flowchart or diagram that represents an example of how data processing works. It seems to illustrate a simple system where input data is processed andresults are generated based on predefined conditions.Here's a breakdown of the elements in the diagram:1. The input statement reads "How many employees live in Calgary?" This indicates that the system is designed to process information about employees who reside in Calgary.2. There are two nodes labeled as 'Employee', which suggests that there might be multiple employee records or data points within the system.3. Each 'Employee' node has fields such as 'ID', 'Name', and 'Location'. The 'Location' field is presumably used to store where each employee resides.4. The diagram includes an 'Employee' node with the 'Location' field set to 'Calgary', which represents a specific data point within the system.5. There are two decision points in the flowchart: 'Model 1' and 'Model 2'. These likely represent different algorithms or methods used for processing the input data.6. The output statement at the bottom of the diagram reads "There are 3 employees living in Calgary". This suggests that after processing the input data, the system has determined thatthere are three employees who live in Calgary.Overall, the meaning of this diagram is to illustrate a simple example of how an input question can be processed through a predefined model or algorithm to generate an output answer based on the available data within a system. It's a basic representation of data processing and does not include specific details about the inner workings of the models or algorithms involved in the process.The result is very impressive and accurate.
Extracting code from images.

Prompt: extract code from the image /path_to_the_imageResult:
```pythonwhile True:byte_buffer.msg = stream_read_pending()byte_buffer.stream.sleep(100)if byte_buffer.msg == None:continuetime.sleep(1 / 60)for i in range(1,12):byte_buffer.message = message + " " + str(i)source_sequence.set("seq_" + byte_buffer.msg + "_" + str(len(byte_buffer.message)))if source_sequence.length < 0:print("Error: Source Sequence Length is less than zero")It's interesting that LLaVa extracted the pseudocode but returned it in Python language.
Reading text from the image.

Prompt: extract text from the image /path_to_the_imageResult:
Nine Presentation Lessons from Steve Jobs1. Show Your Passion2. One Sentence Summary of Product3. The Third Rule4. Use Simplicity to Win the Battle5. Don't Hide Behind Bullet Points6. Make Everything Personal and Relatable7. Create a Hero for Customers8 8. Tell Them Stories About How Your Product Changes Lives9. Keep the Data Clean11. Bring the Hero After a Short Break2. Every Story Needs an Ending3. Don't Read from Notes - Prepare, Practice, and Preach4. Be Yourself and Help You Give Your Best Performance5. Prepare to Give a Good Presentation6. Use a Visual Aid for Better Understanding of the Product7. Tell Them About How Your Product Changes Lives8. Bring the Hero After a Short Break9. Keep the Data Clean10. Don't Read from Notes - Prepare, Practice, and Preach11. Be Yourself and Help You Give Your Best Performance12. Use a Visual Aid for Better Understanding of the Product13. Create a Hero for Customers14. Bring the Hero After a Short Break15. Every Story Needs an Ending16. Don't Hide Behind Bullet Points17. Make Everything Personal and Relatable18. Use Simplicity to Win the Story19. Show Your Passion20. One Sentence Summary of Product21. The Third Rule22. Bring the Hero After a Short Break23. Don't Hide Behind Bullet Points24. Make Everything Personal and RelatableThe image is large, so LLaVa takes a few minutes to encode and decode it. However, the result is spectacular.
Conclusion
--------------
In conclusion, LLaVA-v1.6 is a powerful AI model that offers numerous possibilities and functionalities for image visioning tasks. With its ability to analyze and understand visual data, LLaVA-v1.6 has numerous applications in various fields, including healthcare, finance, and education. While the model has some limitations, it is a valuable tool for researchers and developers looking to explore the possibilities of AI and machine learning.