Using Oracle Database 23ai for Generative AI RAG implementation, part -1

(Image source: OpenAI: DaLLE, generated for blog post)
At the recent CloudWorld event, Oracle introduced Oracle Database 23c, its next-generation database, which incorporates AI capabilities through the addition of AI Vector Search to its converged database. This vector search feature allows businesses to run multimodal queries that integrate various data types, enhancing the usefulness of GenAI in business applications. With Oracle Database 23c, there’s no need for a separate database to store and query AI-driven data. By supporting vector storage alongside relational tables, graphs, and other data types, Oracle 23c becomes a powerful tool for developers building business applications, especially for semantic search needs.
In this two-part blog series, we’ll explore the basics of vectors and embeddings, explain how the Oracle vector database works, and develop a Retrieval-Augmented Generation (RAG) application to enhance a local LLM.
In this post, we will cover the following steps:
Install and configure Oracle Autonomous Database Free (ADB-Free) in a Docker container.
Optionally configure DBeaver to explore the database (optional).
Create a Jupyter notebook to parse files and store/search embeddings in the Oracle ADB-Free database.
Before we dive into the installation and configuration process, let's clarify a few concepts, such as embeddings and vectors in Generative AI. If you are already familiar with these concepts, feel free to skip this section.
Let's start from the term Vector: In mathematics, a vector is an object that represents both the value and direction of a quantity in any dimension.
# Creating a vector as an array
!pip install numpy import numpy as npvector = np.array([1, 2, 3, 4, 5])
print("Vector of 5 elements:", vector)Output:
Vector of 5 elements: [1 2 3 4 5]In the context of Generative AI, vectors are used to represent text or data in numerical format, allowing the model to understand and process it. This is necessary because machines only understand numbers, so text and images must be converted into vectors for the Large Language Models (LLM) to comprehend.
The following is pseudocode that converts a motivational text into tokens using the Phi-2 model. We use the AutoTokenizer class from Hugging Face to encode the text into vectors and decode it back into text.
!pip install transformersfrom transformers
import AutoTokenizer from huggingface_hub
import interpreter_login
# Use your API KEY of Hugging Face here and click enter ;-)interpreter_login()
model_name='microsoft/phi-2'
tokenizer = AutoTokenizer.from_pretrained(model_name,token="HF_TOKEN")
txt = "We must always change, renew, rejuvenate ourselves; otherwise, w\ e harden."token = tokenizer.encode(txt)
print(token)
decoded_text = tokenizer.decode(token)
print(decoded_text)Output:
[1135, 1276, 1464, 1487, 11, 6931, 11, 46834, 378, 6731, 26, 4306, 11, \ 356, 1327, 268, 13] We must always change, renew, rejuvenate ourselves; otherwise, we harden. Vectors alone are not sufficient for LLMs because they only capture basic numerical features of a token, without encoding its rich semantic meaning. Vectors are simply a mathematical representation that can be fed into the model. To capture the semantic relationships between tokens, we need something more—embeddings.
Embedding: An embedding is a more sophisticated version of a vector, usually generated through training on large datasets. Unlike raw vectors, embeddings capture semantic relationships between tokens. This means that tokens with similar meanings will have similar embeddings, even if they appear in different contexts.
Embeddings are what enable Large LLMs to grasp the subtleties of language, including context, nuance, and the meanings of words and phrases. They arise from the model’s learning process, as it absorbs vast amounts of text data and encodes not just the identity of individual tokens but also their relationships with other tokens.
Typically, embeddings are generated through techniques such as Word2Vec, GloVe, or using sentence-transformers. Here’s an example of how OpenAI Embeddings can be used to generate embeddings from input texts: Lion, Tiger and IPhone.
!pip install sentence-transformers
from sentence_transformers import SentenceTransformer
encoder = SentenceTransformer('all-MiniLM-L12-v2')
txt = "Lion"
embeddings = encoder.encode(txt, batch_size=10)
print (embeddings)Output:

Vector database. Also known as a similarity search engine, is a specialized database designed to store and efficiently retrieve vectors. These databases are optimized for performing nearest neighbour searches (i.e., finding the most similar item based on their embeddings) in high-dimensional vector spaces. Unlike traditional relational databases, vector databases can compare vectors directly without needing explicit queries about attributes.
Key Characteristics of a Vector Database:
Stores embeddings: Instead of storing raw data (like text or images), it stores the vector representations (embeddings) of this data.
Specialized indexing: Uses techniques like HNSW (Hierarchical Navigable Small World graphs) or FAISS (Facebook AI Similarity Search) to index and search for similar vectors efficiently.
Scalability: Can handle millions or billions of vectors and perform fast similarity searches even in high-dimensional spaces.
Let’s go by an example:
1. Movie A: “A notorious pirate characterized by his slightly drunken swagger”
– Embedding: [0.9, 0.1, 0.8, ...]
2. Movie B: “A pirate who wants to confront Jack for stealing her ship.”
– Embedding: [0.85, 0.15, 0.75, ...]
If you query the database with the embedding of Movie A, it will also return Movie B because their embeddings are close in the vector space, indicating they have similar content.
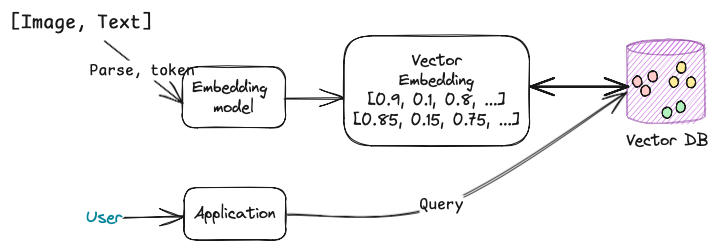
Vector databases can be used in various scenarios:
Semantic Search: For example, when you search for artificial intelligence in a document database, the vector database can find documents that contain related topics like machine learning or neural networks.
Image Retrieval: Find similar images based on their visual features, such as finding all images of dogs in a large photo collection.
Recommendation Systems: Quickly find and recommend products, articles, or media similar to what a user is interested in.
If you would like to learn more about embeddings and vectors, please refer to the sample chapter of my book, Getting Started with Generative AI.
Now that we have sufficient theories, let's explore using Oracle Database to store and query embeddings.
I will use a local mini server powered by Proxmox to install and configure the Oracle Autonomous Database Free (ADB-Free) in a Docker container. My setup is outlined below:
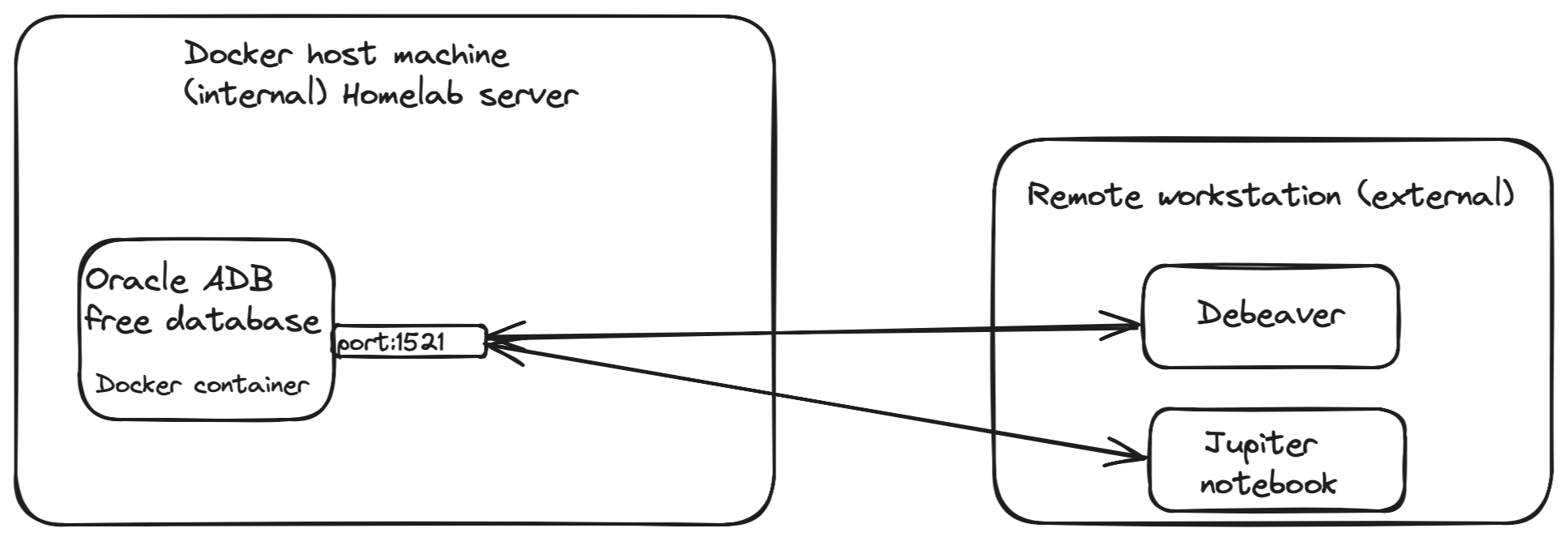
Step 1. Install and configure the database
Run the following bash command:
docker run -d \ -p 1521:1522 \ -p 1522:1522 \ -p 8443:8443 \ -p 27017:27017 \ -e WORKLOAD_TYPE=ATP \ -e WALLET_PASSWORD=Welcome_12345 \ -e ADMIN_PASSWORD=Welcome_12345 \ --cap-add SYS_ADMIN \ --device /dev/fuse \ --name adb-free \ ghcr.io/oracle/adb-free:latest-23aiHere, we already setup the Admin and Wallet password: Welcome_12345
If everything goes fine, a new database instance named ATPDB will be created.
Oracle Database Actions application like web sql-developer will be accessible through the url https://IP_ADDRESS:8443/ords/sql-developer
You can use this web application to manipulate the database, such as creating schemas and users or querying the database.
Step 2. Wallet setup.
Therefore, Oracle ADB-Free is not accessible directly; we need a wallet to communicate with the database. Create a new directory to your host machine named "/scratch/tls_wallet" and copy the wallet to the docker host machine by the following command:
docker cp adb-free:/u01/app/oracle/wallets/tls_wallet /scratch/tls_walletPoint TNS_ADMIN environment variable to the wallet directory.
export TNS_ADMIN=/scratch/tls_walletIn my case, since I plan to connect remotely, I need to replace 'localhost' in $TNS_ADMIN/tnsnames.ora with the remote host's FQDN.
sed -i 's/localhost/my.host.com/g' $TNS_ADMIN/tnsnames.oraNow, archive (zip) the wallet for farther use.
zip -j /scratch/tls_wallet.zip /scratch/tls_wallet/*Step 3. Create a new User/Schema
Log in to the database as the administrator user (= sys).
docker exec -it adb-free sqlplus sys/Welcome_12345@myatp_medium.adb.oraclecloud.com as sysdbaWhere, myatp_medium.adb.oraclecloud.com is the database Service name from the tnsnames.ora file.
Create a regular database user SCOTT, and grant it the CONNECT and RESOURCE roles.
CREATE USER SCOTT
IDENTIFIED BY Welcome_12345
DEFAULT TABLESPACE users
TEMPORARY TABLESPACE temp
QUOTA UNLIMITED ON users;
GRANT CONNECT, RESOURCE TO SCOTT;Logout with the command
exitVerify you can connect with the new user. Use the following command from any terminal:
docker exec -it adb-free sqlplus SCOTT/Welcome_12345@myatp_medium.adb.oraclecloud.comStep 4. Start coding on Python :-)
I will use Jupyter Notebook with Miniconda to run the Python application; however, you can use your preferred IDE, such as Visual Studio Code, to execute it.
Anyway, if you are straggling to install and configure Jupyter note or Miniconda, please refer to the sample chapter of my book, Getting Started with Generative AI.
Create a new python Jupyter note book and add the following statement.
!pip install oracledb sentence-transformers ociThe command will install all the necessary packages we need.
Download the file named Generative_AI_FAQ.txt from the link and save it in the same directory as your Jupyter Notebook file.
Note that, fragment of the python code was taken from the blog post Setting Up Vector Embeddings and Oracle Generative AI with Oracle Database 23ai and remains unchanged.
Load the file from the directory:
import osdef loadFAQs(directory_path): faqs = {} for filename in os.listdir(directory_path): if filename.endswith(".txt"): file_path = os.path.join(directory_path, filename) with open(file_path) as f: raw_faq = f.read() faqs[filename] = [text.strip() for text in raw_faq.split('=====')] return faqsfaqs = loadFAQs('.')Each question and answer is separated by the '=====' symbol, so we will use '=====' as the delimiter.
Add the following statement into a new cell.
docs = [{'text': filename + ' | ' + section, 'path': filename} for filename, sections in faqs.items() for section in sections]Connect to the database schema SCOTT and create a table:
import oracledbconnection = oracledb.connect(user="scott", password="Welcome_12345", dsn="myatp_medium", config_dir="/home/shamim/projects/tls_wallet", wallet_location="/home/shamim/projects/tls_wallet", wallet_password="Welcome_12345")table_name = 'genaifaqs'with connection.cursor() as cursor: cursor.execute(f""" CREATE TABLE IF NOT EXISTS {table_name} ( id NUMBER PRIMARY KEY, payload CLOB CHECK (payload IS JSON), vector VECTOR )""")Tokenise and embedding the contents of the file as shown below.
from sentence_transformers import SentenceTransformerencoder = SentenceTransformer('all-MiniLM-L12-v2')data = [{"id": idx, "vector_source": row['text'], "payload": row} for idx, row in enumerate(docs)]texts = [row['vector_source'] for row in data]embeddings = encoder.encode(texts, batch_size=10)import arrayfor row, embedding in zip(data, embeddings):row['vector'] = array.array("f", embedding)Store the vectors into the table genaifaqs
import jsonwith connection.cursor() as cursor:cursor.execute(f"TRUNCATE TABLE {table_name}")prepared_data = [(row['id'], json.dumps(row['payload']), row['vector']) for row in data]cursor.executemany(f"INSERT INTO {table_name} (id, payload, vector) VALUES (:1, :2, :3)", prepared_data)connection.commit()Here, you can print any row from the notebook or connect to the database to explore the rows of the table.
cr = connection.cursor()r = cr.execute("SELECT * FROM genaifaqs f where rownum =1")print(r.fetchall())This will print very much similar output:
[(24, {'text': 'Generative_AI_FAQ.txt | Q25: What is deepfake technology?\nA: Deepfake uses AI to create realistic, altered videos or images of people.', 'path': 'Generative_AI_FAQ.txt'}, array('f', [-0.0007201445405371487, -0.0258498378098011, 0.007152569945901632, -0.003656314220279455, -0.0020476249046623707, 0.02976640872657299, -0.0202650036662817, -0.09278019517660141, 0.03025302290916443, 0.04996906593441963, -0.03872310370206833, -0.01933300867676735, -0.007471167482435703, -0.01518948096781969, -0.042043089866638184, -0.0028244946151971817, 0.022211210802197456, 0.12178391218185425, -0.03381387144327164, -0.0340578518807888, 0.09609763324260712, 0.015460986644029617, 0.019726844504475594, -0.0542815737426281]))] Let's try a semantic search over the table, add the following SQL query:
topK = 4sql = f"""SELECT payload, vector_distance(vector, :vector, COSINE) AS score FROM {table_name} ORDER BY score FETCH FIRST {topK} ROWS ONLY"""Here, we used COSINE metric to retrieve values from the tables. You can use different metrics like MANHATTAN or JACCARD metric to calculate the distance.
Now, we can ask any question related to our question and answer file about the Generated AI and get the semantic result.
question = "What are GANs?"embedding = list(encoder.encode(question))vector = array.array("f", embedding)results = []with connection.cursor() as cursor: for (info, score,) in cursor.execute(sql, vector=vector): text_content = info.read() results.append((score, json.loads(text_content)))print(results)The code above should return a result that closely resembles the one shown below:
[(0.27902800283631, {'text': 'Generative_AI_FAQ.txt | Q6: What are GANs?\nA: GANs are models with two networks—generator and discriminator—that work together to produce realistic outputs.', 'path': 'Generative_AI_FAQ.txt'}), (0.5485436443629503, {'text': 'Generative_AI_FAQ.txt | Q26: Are deepfakes harmful?\nA: They can be used maliciously, but also have valid applications in entertainment.', 'path': 'Generative_AI_FAQ.txt'}), (0.5558175537684329, {'text': 'Generative_AI_FAQ.txt | ', 'path': 'Generative_AI_FAQ.txt'}), (0.5777062333924782, {'text': 'Generative_AI_FAQ.txt | Q22: What is AI-generated art?\nA: Artwork created by AI models trained on visual data to generate creative visuals.', 'path': 'Generative_AI_FAQ.txt'})]At this point, I encourage you to experiment with different metrics, such as MANHATTAN, and use various files to work with vectors and semantic search. In the follow-up blog post, we will move forward and add functionality to communicate with a local LLM for developing RAG application.
As usual the source code is available at GitHub.